AI Ops & Analytics for Production AI
Reduce failures, control cost, and keep answers trustworthy (LLMOps).
When your AI app is live, you need visibility before things break. We implement practical AI operations systems that track quality, latency, and spend in real time, then layer in LLM observability, semantic routing, prompt caching, and eval suites so teams can fix issues fast and scale safely.
Delivery Snapshot
- Semantic model routing
- Prompt caching & optimization
- Automated eval suites
Expected outcomes outcomes
Measurable results that improve delivery speed, resilience, and ROI.
Why teams choose us
Production LLM operations that scale with your business.
Cost-optimized inference
Semantic routing and caching reduce API costs without sacrificing output quality.
Safety-first guardrails
Input/output filters block prompt injections, toxic content, and PII leakage.
CI/CD-integrated evals
Automated quality gates prevent model regressions from shipping.
Core capabilities
The complete operations stack for production LLMs.
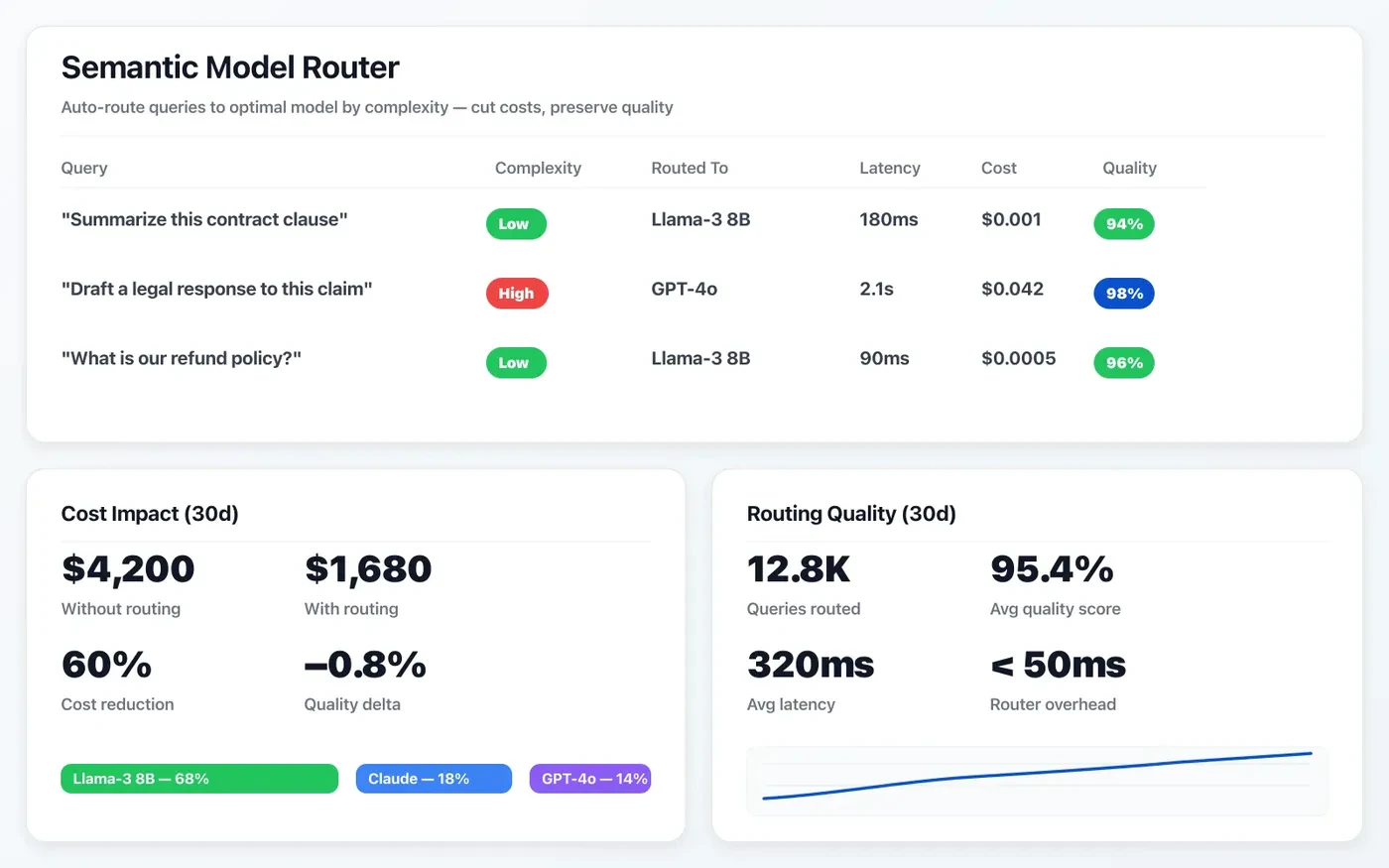
Semantic model routing
Route queries to the optimal model based on complexity — cut costs on simple tasks, preserve quality on hard ones.
Requests are routed to the best-fit model by latency, cost, and quality thresholds to optimize production performance.
- Policy routing by task type and SLA
- Fallback chains for outage and degradation
- Per-route telemetry for cost and quality
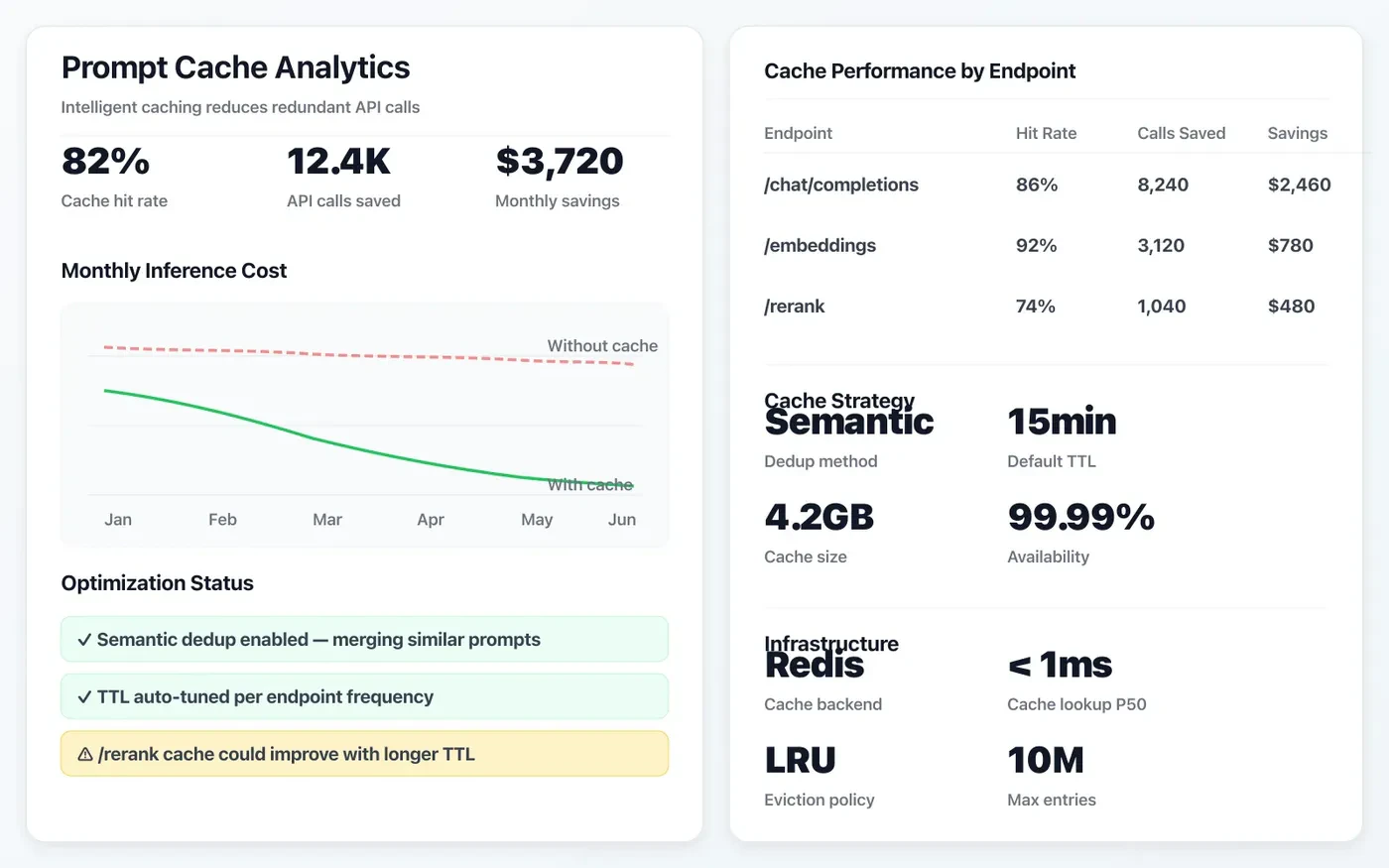
Prompt caching & optimization
Intelligent caching layers reduce redundant API calls and slash inference costs by up to 60%.
We reduce token spend and response time through reusable prompt patterns, cache layers, and optimization loops.
- Deterministic cache keys for repeated queries
- Prompt template versioning and experiments
- Cost-per-request monitoring and guardrails
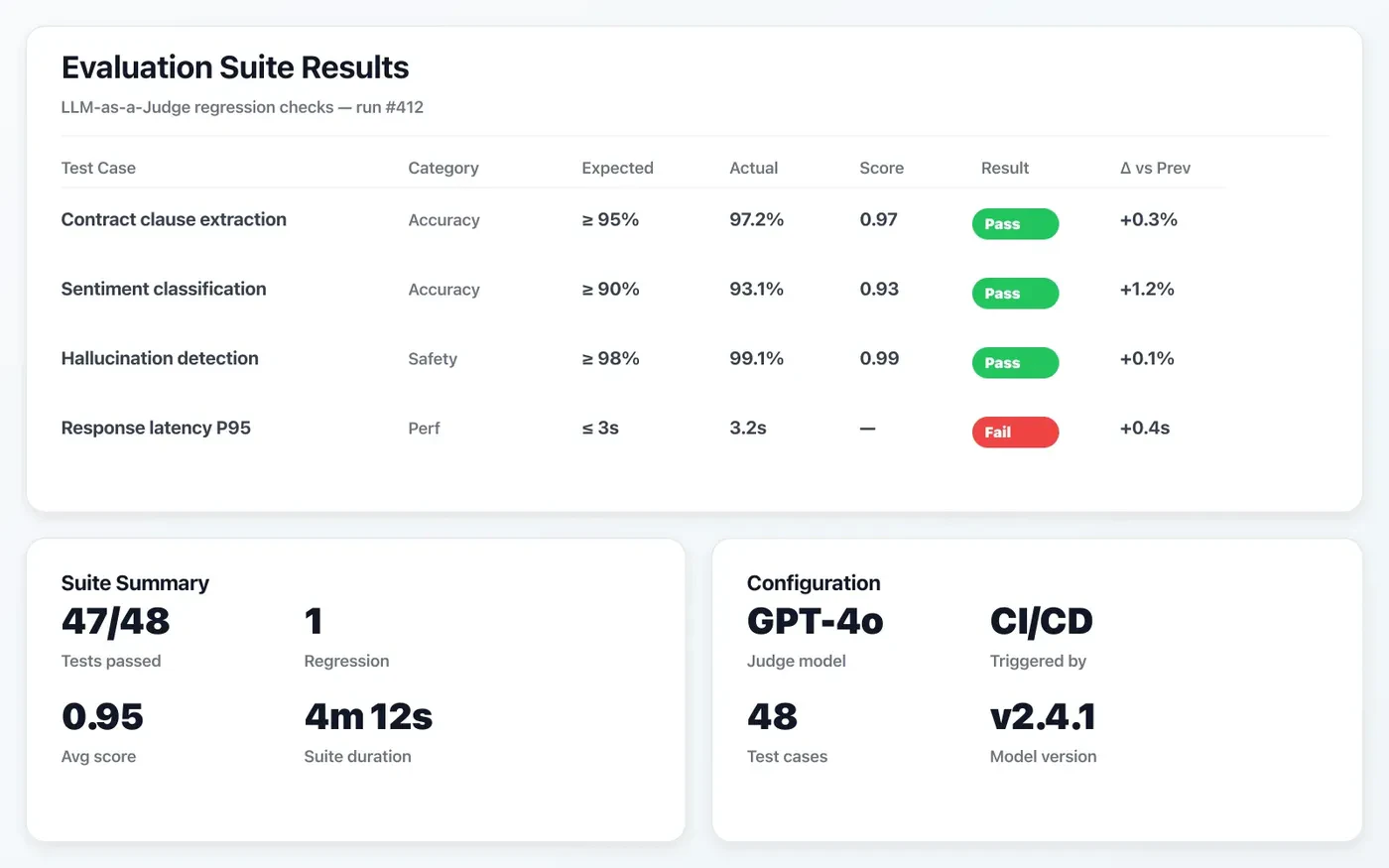
Automated eval suites
LLM-as-a-Judge frameworks catch regressions before they reach production.
Continuous evaluations catch regressions early, so model and prompt updates can ship with confidence.
- Golden dataset benchmark automation
- Task-specific quality scoring pipelines
- Release gates tied to eval thresholds
Where it applies
Practical scenarios that map to measurable outcomes.
Multi-model cost optimization
Route workloads across GPT-4, Claude, and open-source models.
- Complexity-based routing
- Fallback chains
- Cost tracking per query
AI safety compliance
Enforce output policies for regulated industries.
- PII redaction
- Toxicity filtering
- Audit logging
Continuous model evaluation
Catch quality regressions before they reach users.
- Golden dataset tests
- A/B model comparison
- Drift detection
How we work
A focused, milestone-driven approach that keeps momentum and clarity.
Infrastructure audit
Infrastructure audit
Assess current LLM usage, costs, latency profiles, and safety posture.
Pipeline design
Pipeline design
Architect routing, caching, guardrails, and eval frameworks.
Implementation
Implementation
Build and integrate with your existing CI/CD and monitoring stack.
Optimisation loop
Optimisation loop
Continuous cost/quality tuning with automated alerts and dashboards.
Frequently asked questions
Answers to common project and collaboration questions.
What is semantic routing?
How do you test LLM outputs in CI/CD?
Can you add guardrails to our existing LLM setup?
Ready to operationalize your GenAI stack?
Let us build the LLMOps infrastructure that makes your AI reliable, safe, and cost-efficient.