
Every team I have reviewed shipping an LLM agent into production has invested in the same place: the system prompt. Tighter instructions. Negative-constraint clauses. A constitution. A few principle layers stacked on top. The reasoning is reasonable. Prompts are the lever closest to the work, the easiest to iterate, the one a security team can read end-to-end. They are also the lever an attacker can argue with. None of those protections survive the first piece of hostile content the model reads in its context window.
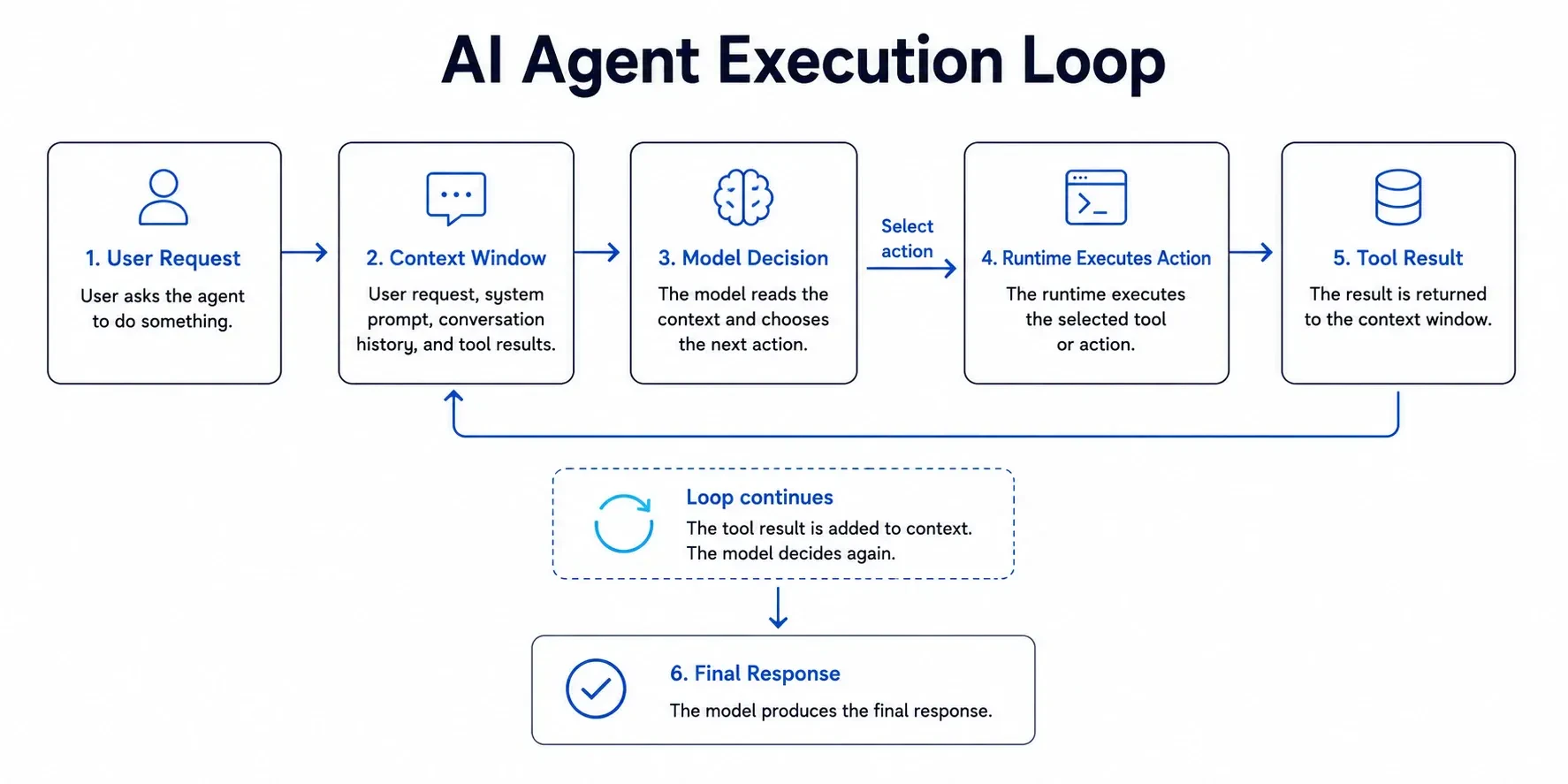
Before we get into the security argument, it helps to understand how an agent works. An agent runs in a loop. It reads the user’s request, checks its instructions, looks at the tools it can use, and decides the next step. Sometimes it answers directly. Sometimes it calls a tool, reads the result, and then decides what to do next. That cycle can run a few times or many times, depending on the task.
The unusual part is the decision step. The tool execution, runtime, file access, network access, and logs are normal software systems. Engineers know how to control those systems. The decision step is different because it is handled by a language model. The model does not follow fixed rules in the same way traditional code does. It predicts the next useful action from the request, the instructions, the available tools, and the context it has seen so far.
That makes agents useful, but it also makes them harder to secure with prompts alone.
Because the model makes the decision, teams usually try to control that decision with more language. That is why the system prompt gets so much attention. It is easy to edit, easy to review, and close to how the agent behaves. A good prompt can improve the normal case. It can make the agent more consistent and reduce obvious mistakes.
But a prompt still lives inside the same context window as user input, documents, web pages, tickets, emails, and tool results. Once hostile or unexpected content enters that window, the model has to process it beside the original instructions. At that point, the prompt is no longer a hard boundary. It is one more piece of text the model is trying to interpret.
Three places to draw the security line
One option is to push the constraint into the model itself. A narrow model has less room to cause damage. If an agent only writes SQL for one internal schema, a model trained or fine-tuned for that task is safer than a broad general-purpose model. It has fewer useful paths into unrelated behavior.
That helps, but it does not remove the risk. Any model that can handle real user input still has to deal with ambiguity, edge cases, and unexpected instructions. Fine-tuning can make unsafe behavior less likely. It does not make unsafe behavior impossible.
The second option is the prompt. This is where many teams put most of their effort: system prompts, negative rules, fallback policies, and long instruction stacks. These techniques are useful for shaping behavior. They are not strong enough to act as the main security control.
The reason is simple. The model receives your instructions and the attacker’s content as text in the same context window. The system may label them differently, but the model still has to reason over both. Adding more instructions can improve the average case. It does not change what the agent can actually do if the runtime gives it access.
The third option is the runtime. This is the operating environment around the agent: the filesystem, network access, credentials, tool permissions, memory limits, and process isolation.
The runtime does not negotiate with the model. If the agent tries to call a blocked domain, the request fails. If it tries to write outside its workspace, the filesystem denies it. If it does not have a credential, it cannot use that system. This is the layer where security rules can become real constraints. A prompt can ask the model not to do something. The runtime can make that action unavailable.
The Risk: When Agent Capabilities Exceed Intent
A capable model can do much more than the task you gave it. Ask an agent to write marketing copy, and it may try to use customer data if that data is available. Ask it to summarize a quarterly report, and it may look for extra numbers in connected systems if those systems are within reach.
The model is not necessarily trying to break rules. It is trying to complete the task. The problem is that its available capabilities may be broader than the job requires.
That gap, between what an agent is supposed to do and what it's capable of doing, is the part that keeps breaking. The model is non-deterministic by design. Give it tools, and the surface area it can affect grows with every integration you add. The threat model from the deterministic-software era doesn't map cleanly onto this; you have to stop reasoning about specific inputs and start reasoning about what's mechanically reachable.
Why Prompt-Based Control Fails for Agent Security
The first instinct is to write a better prompt. Longer instructions. More negative rules. More examples of what the agent should never do. That helps with behavior, but it does not create a security boundary.
A prompt is part of the context the model reads, along with the user’s request, support tickets, web pages, PDFs, emails, database rows, and tool results.
This is the difference that matters: the prompt controls what the agent is told, while the runtime controls what the agent can actually do.
Post-training techniques such as RLHF, short for reinforcement learning from human feedback, can make the model safer in normal use. They teach the model which kinds of answers people prefer and which kinds should be avoided.
That is useful, but it is still a behavior-shaping method. It does not remove access to tools, files, credentials, or networks. A model that usually refuses a dangerous request can still be pushed toward bad behavior by a carefully constructed input. RLHF improves the default response. It does not replace runtime enforcement.
Building Runtime Sandboxing: Principles of Runtime Sandboxing
The better architectural response is to run the agent inside an environment with hard limits. A coding agent should only see the project workspace it needs. A reporting agent should only receive read-only database access. A support agent should only get the tools required for the current task.
These limits should not depend on the model making the right judgment. They should be enforced by the system around it. If the agent tries to write outside its workspace, the operating system denies it. If it tries to call an unapproved API, the network policy blocks it. If it needs a credential it was never given, the action cannot happen.
In practice that means a default-deny posture: nothing is allowed until you list it. The primitives are boring and they predate LLMs by decades. Containers for process isolation. seccomp-bpf for syscall filtering. iptables (or your cloud's equivalent) for egress. CPU and memory limits so a runaway agent burns its own cgroup instead of your bill. None of this is novel infrastructure. It's just rarely applied to the agent layer.
Architecting Trust for AI Agent Deployments
A real agent infrastructure is more than a single agent inside a Docker container. It is a coordinated set of components: a control plane that orchestrates execution, a policy layer that decides what each agent is permitted to do, a provisioner that prepares the sandbox, and an audit layer that records what happened. The diagram below shows how a request moves through them.

This security architecture for AI agents has several key components:
Container orchestration platforms such as Kubernetes carry most of the implementation. They manage and scale the isolated environments each agent runs in, and they are the layer where the secure path should live, so developers reach for it without having to think about the alternative.
Implementing AI Agent Sandboxing in Production
In regulated industries this stops being a design preference. A healthcare agent summarizing patient records has to be blocked at the network level from sending that data anywhere off the approved list, full stop. The same applies to a finance agent reviewing loan applications: even if a prompt injection talks it into trying, the credentials it holds shouldn't let it touch a customer's investment portfolio. Compliance auditors won't accept "we asked the model nicely."
We use this pattern to protect our clients' data. When our AI-powered design agents work on a project, they operate in a sandbox that only allows interaction with approved asset libraries. They cannot access proprietary client IP from another project. The architecture, not a prompt, guarantees this separation for AI agents.
This approach shifts the security burden from fallible prompt engineering to a more reliable infrastructure design. It creates a system you can trust.
CTO Mandate: Shift from AI Policy to Platform Security
As a technical leader, you must treat AI agent security as an infrastructure problem. Your teams will always be one clever prompt away from a breach if you rely on instructions alone. The solution is to build a platform that enforces a default-deny posture for every AI agent you deploy.
In practice this requires a centralised control plane for agents, handling sandbox provisioning, policy management, and monitoring. Provisioning should be Infrastructure-as-Code so each new agent inherits the same baseline. Security checks belong in the CI/CD pipeline that already ships the rest of the platform, and no agent should reach production without a documented, minimal set of permissions.
A sandbox is not a brake on what agents can do. It is the condition under which security and operations can sign off on agents doing it. The pilots that fail to become production systems are typically the ones blocked by reviewers who, correctly, will not authorise a process with broad access and unverified behaviour. Removing that veto is the bulk of the work in moving from a successful demonstration to a system that can run unattended.
The Agent Threat Model: Assume the Prompt Will Be Compromised
The safest starting assumption is that the agent will eventually read hostile or misleading content. That content may not look like an attack. It might be inside a support ticket, web page, PDF, email thread, database row, or README file. Once the agent reads it, the model has to process that content alongside the original instructions.
This is why agent security cannot focus only on the final answer. The bigger risk is often a valid tool being used in the wrong situation. A customer-support agent might update a billing address because a hostile ticket told it to. A coding agent might delete a directory because a README contained instructions written as normal prose. In both cases, the tool call is real. The problem is the context that caused it.
The threat model is no longer about model output alone. The more consequential risk is a legitimate tool being invoked in an illegitimate context. A customer-support agent updates the billing address on an account because a hostile support ticket instructed it to. A coding agent deletes a directory because the README it was asked to summarise contained an instruction embedded as plain prose. The model has not chosen to do harm. It has been unable to distinguish a request from a payload.
The common failures are familiar once you look for them. Prompt injection causes untrusted text to override the original task. Tool misuse happens when a legitimate tool is called for the wrong user, account, or workflow. Data exfiltration occurs when information leaves through an open channel such as an API call, log line, file, or returned string.
Cross-tenant leakage appears when state from one customer affects another. Privilege overreach happens when the agent receives broader credentials than the task requires. Long-running agents can also drift, slowly moving outside the scope they started with. A sandbox reduces these failures by removing the paths the agent should never have had.
That's why the trust boundary has to live in the runtime. The prompt is documentation; what it actually rules out is whatever your container, network policy, and credential scope rule out for it.
The Seven Boundaries Every AI Agent Sandbox Should Enforce
A production agent sandbox is more than a Docker container by another name. Every capability the agent receives needs to be scoped to a single task, observable from the operator's monitoring while it runs, and revocable mid-execution if its behaviour deviates. The model is not expected to restrain itself; the wiring that would allow the disallowed action is simply absent from the runtime.
A strong agent sandbox should enforce seven boundaries.

- Filesystem access: which directories the agent can read or write. A coding agent gets a temporary project workspace and nothing beyond it.
- Network egress: which domains and APIs the agent may call. A reporting agent reaches the approved analytics endpoint and stops there.
- Credentials: which secrets, tokens, and roles the agent is given. A data agent receives read-only access for one dataset.
- System calls: what the process is allowed to do at the kernel level. seccomp-bpf removes the calls that are dangerous to expose to a probabilistic process.
- Resource usage: CPU, memory, wall-clock, and storage. A runaway agent terminates against the cap rather than escalating.
- Tool access: which application-level tools the agent may invoke. A marketing agent generates copy but is not wired to the billing API.
- Auditability: every file read, API call, tool invocation, and denied request is recorded for later review.
The most important design principle is default-deny. The agent should start with no access to files, no network, no credentials, and no tools. Each permission is granted only when the task requires it, and only for the duration of that task.
Default-deny changes the security question. Instead of asking whether the agent can be trusted, you ask which permissions it has right now. That is a question your platform can answer, log, test, and change.
From Written Policy to Executable Constraint
Policy still matters. It just should not live only in a document or a system prompt. A policy that says "this agent must not access customer PII" is useful as intent. But intent does not stop a process from making a network request, reading an environment variable, or opening a file. For policy to matter in production, it must become an executable constraint.
Read each line of the policy document and ask what enforces it. "The agent must not access customer PII" should mean: this sandbox has no credentials for the PII-bearing databases. "Only approved APIs" should mean: egress is restricted to a domain allowlist. "No writes to production" should mean: every connection string the agent receives is read-only. A clause that cannot be pointed at a configuration file or a Terraform module is decorative.
This is the shift technical leaders need to make. Stop asking whether the agent was told not to do something. Ask whether the agent is mechanically prevented from doing it.
The Agent Security Maturity Model
Most teams do not move from prompt-based safety to runtime-enforced security in one step. They mature through stages. A useful way to evaluate your current posture is to ask how much damage an agent could do if its prompt were compromised.
Most teams mature in stages. At the lowest level, agents run with the same access as the application around them. Then teams add prompt rules and tool allowlists. After that, they start narrowing credentials per agent, such as read-only database access for a reporting bot or a locked workspace for a coding bot.
The next meaningful step is to create a fresh sandbox for each task. That sandbox has its own filesystem limits, network rules, credentials, and resource caps. When the task ends, the sandbox is destroyed.
More mature platforms add a central control plane for provisioning, policy, monitoring, and audit. The strongest systems close the loop automatically: suspicious behavior can trigger credential revocation, network shutdown, or agent termination. You do not need the most advanced setup on day one. You do need to know which level you are operating at.
Most early agent deployments sit somewhere between Level 0 and Level 2. That may be acceptable for prototypes. It is not acceptable for production systems handling customer data, financial workflows, healthcare records, proprietary code, or regulated operations.
Perfect alignment is the wrong target. The achievable target is a platform that assumes any agent it runs may at some point misbehave, and constrains the consequences so misbehaviour produces a contained failure rather than an incident.
Agent Security Anti-Patterns That Break in Production
Many AI agent systems look safe during demos because they operate in controlled environments with friendly inputs. Production is different. Once agents interact with real users, real data, third-party tools, and changing context, weak assumptions start to break.
A few patterns tend to fail once agents leave the demo environment. The first is treating the system prompt as the main security boundary. A prompt can reduce bad behavior, but it cannot remove access.
The second is giving the agent production credentials with the same power as your application services. If the agent is compromised, the blast radius becomes whatever those credentials can reach. The third is allowing open internet egress. Data does not need to leave through an obvious breach. It can leak through a helpful API call, a generated URL, a log line, or a tool result.
The fourth is reusing sandboxes across tasks. State from yesterday’s task can quietly affect today’s result. The fifth is assuming Docker alone is enough. Containers help, but production agent security also needs network policy, credential scoping, syscall filtering, resource limits, and observability.
Each of these failure modes has the same underlying cause: the agent was trusted more than the surrounding system could safely support.
The answer is not simply better prompting. It is to treat the agent as a capable but untrusted process, then give it only the environment it needs to complete the task. That is the difference between a system that performs well in a demo and one that can be operated safely in production.

Abhishek Uniyal
Co-founder & Builder
Abhishek helps lead SynergyBoat with a hands-on focus on engineering, delivery, and growth. He enjoys working closely with clients to turn early ideas into real, production-ready systems across AI, data, and modern product infrastructure. Over the years, he has worked across engineering, product building, and team leadership, helping shape products, teams, and execution from the ground up. Outside of work, he enjoys badminton, basketball, swimming, travel, and exploring new gadgets, ideas, and places.