
Introduction
Retrieval-Augmented Generation (RAG) is transforming how modern applications access and use knowledge. Instead of relying solely on a model’s training data, RAG systems bring in relevant, fresh, and domain-specific context at runtime—bridging the gap between static LLMs and real-world intelligence.
This guide unpacks the building blocks of a production-grade RAG system—from architecture decisions and document processing to vector search, performance tuning, and evaluation metrics. Whether you’re creating an internal research assistant, customer support bot, or AI-driven PDF tool, this foundation will help you ship smarter, faster, and more reliable RAG applications.
The Foundation of RAG systems
RAG stands for Retrieval-Augmented Generation, a paradigm where a language model is enhanced with dynamic, relevant context from a connected knowledge base. Instead of asking the model to “remember everything,” RAG systems retrieve information on-the-fly to ground the response.
Why it matters:
- Keeps outputs accurate and up-to-date
- Works well with private, enterprise, or niche datasets
- Enables AI to explain and cite its sources
Common use cases:
- Legal and contract analysis
- Research copilots and assistants
- Enterprise knowledge search
- Customer support bots
Core Workflow: How Retrieval-Augmented Generation Works
- Knowledge Base Creation: documents, PDFs, and structured data are parsed, chunked, embedded, and stored.
- Retrieval: when a user asks something, relevant chunks are retrieved based on vector similarity and optional keyword filters.
- Generation: the LLM uses retrieved context to generate a grounded response.

Capabilities of Modern RAG Applications
Smart Document Analysis
Users upload PDFs and instantly receive AI-powered summaries, bullet-point insights, and extracted metadata. It saves time and cognitive load during legal reviews, research reading, or market analysis.
Interactive Chat Interface
Static documents become interactive. Users can ask natural language questions and receive contextual answers from within the document, navigating complex reports conversationally.
Real-time Processing
Thanks to OpenAI’s streaming APIs and frameworks like Next.js 14, responses flow in real-time, boosting perceived performance and keeping the interaction smooth.
Offline Capabilities
Even the best systems face interruptions. Production-grade RAG apps monitor connectivity and inform users gracefully if the chat fails or the connection is lost.
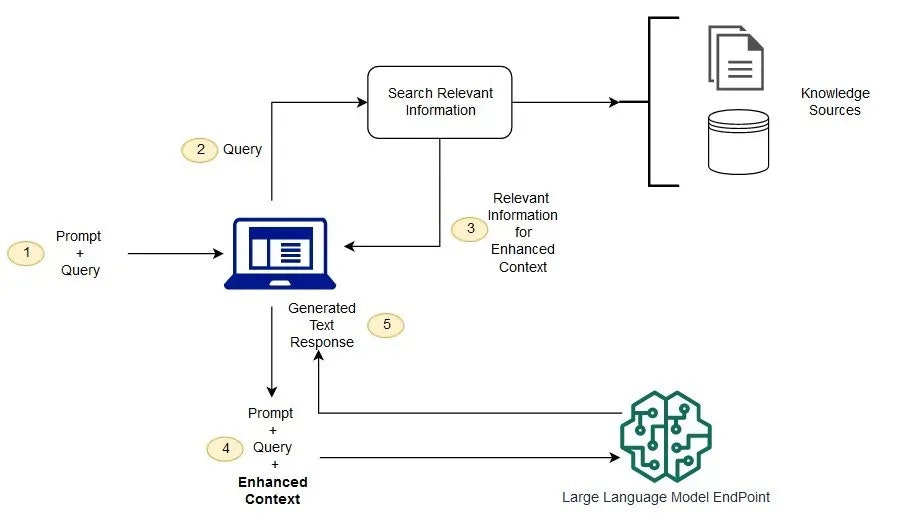
Technical Architecture Deep Dive
Frontend Framework Selection
The application leverages Next.js 14 with the App Router, providing several architectural advantages:
- Server Components: Reduce client-side JavaScript bundle size and improve initial page load times
- Streaming: Built-in support for streaming UI updates, crucial for RAG response rendering
- API Routes: Seamless backend integration for document processing pipelines
- Static Optimization: Automatic static generation where possible, improving performance
The UI layer uses Tailwind CSS with a custom theme configuration supporting both light and dark modes. This approach ensures consistent styling while maintaining flexibility for future design iterations.

Document Processing Pipeline
The heart of any RAG system lies in its document processing pipeline. Our implementation follows a sophisticated multi-stage approach:
Stage 1: Ingestion and Parsing
When users upload PDFs, the system first extracts text content while preserving document structure. This involves:
- Text Extraction: Using libraries like pdf-parse or pdfplumber to extract raw text
- Structure Preservation: Maintaining information about headings, tables, and formatting
- Metadata Extraction: Capturing document properties, creation dates, and author information
Stage 2: Intelligent Chunking
We use semantic chunking strategies:
- Split at natural breaks like paragraphs and headers
- Add overlapping windows for context retention
- Balance chunk sizes for embedding model limits
// Intelligent chunking strategy
function chunkDocument(text, options = {}) {
const {
maxChunkSize = 1000,
overlap = 200,
preserveStructure = true
} = options;
}
Effective chunking strategies include:
- Semantic Chunking: Splitting at natural break points (paragraphs, sections)
- Overlapping Windows: Including context from adjacent chunks to maintain continuity
- Size Optimization: Balancing chunk size with embedding model limitations
Stage 3: Embedding Generation
Each document chunk is converted to high-dimensional vector representations using OpenAI's embedding models. These embeddings capture semantic meaning, enabling similarity-based retrieval:
async function generateEmbeddings(chunks) {
const embeddings = await Promise.all(
chunks.map(chunk => openai.embeddings.create({
model: "text-embedding-3-small",
input: chunk.content
}))
);
return embeddings.map((embedding, index) => ({
...chunks[index],
embedding: embedding.data[0].embedding
}));
}
Stage 4: Vector Storage
We store vectors in MongoDB Atlas with vector search enabled, alongside metadata.
Vector Search Implementation
The most technically challenging aspect of RAG systems is implementing efficient vector search. Our MongoDB-based approach includes several optimizations:

Index Configuration
db.documents.createIndex({
"embedding": "vectorSearch"
}, {
"vectorSearchOptions": {
"type": "knn",
"dimensions": 1536,
"similarity": "cosine"
}
});
Query Optimization
Vector queries are optimized for both accuracy and performance:
async function searchSimilarChunks(queryEmbedding, options = {}) {
const {
limit = 5,
threshold = 0.7,
filters = {}
} = options;
return await db.collection('documents').aggregate([
{
$vectorSearch: {
index: "vector_index",
path: "embedding",
queryVector: queryEmbedding,
numCandidates: limit * 10,
limit: limit,
filter: filters
}
},
{
$match: {
score: { $gte: threshold }
}
}
]);
}
Hybrid Search Strategies
Advanced RAG systems combine vector search with traditional text search for improved accuracy:
- Semantic Search: Vector similarity for conceptual matches
- Keyword Search: Traditional text matching for exact terms
- Weighted Combination: Balancing both approaches based on query characteristics

Performance Optimizations
Production RAG applications require careful optimization across multiple dimensions:
Memory-Safe Batch Processing
Document processing can be memory-intensive, especially for large PDFs. Key optimizations include:
async function processDocumentInBatches(document, batchSize = 50) {
const chunks = chunkDocument(document);
const batches = [];
for (let i = 0; i < chunks.length; i += batchSize) {
const batch = chunks.slice(i, i + batchSize);
const embeddings = await generateEmbeddings(batch);
await storeBatch(embeddings);
// Prevent memory leaks
if (global.gc) global.gc();
}
}
Streaming Optimizations
Response streaming improves user experience significantly:
async function* streamRAGResponse(query, retrievedChunks) {
const completion = await openai.chat.completions.create({
model: "gpt-4",
messages: [
{
role: "system",
content: buildSystemPrompt(retrievedChunks)
},
{
role: "user",
content: query
}
],
stream: true
});
for await (const chunk of completion) {
if (chunk.choices[0]?.delta?.content) {
yield chunk.choices[0].delta.content;
}
}
}
Quality Assurance and Evaluation
Production RAG systems require comprehensive evaluation frameworks:
Retrieval Metrics
- Precision@K: Proportion of relevant documents in top-K results
- Recall@K: Coverage of relevant documents in top-K results
- Mean Reciprocal Rank (MRR): Average inverse rank of first relevant result
Generation Quality
- Faithfulness: Response grounding in retrieved context
- Answer Relevance: Response relevance to user query
- Context Precision: Quality of retrieved context
Future Directions
Multimodal RAG
Extending beyond text to include images, tables, and other media types in document understanding and retrieval.
Agent-Based RAG
Integrating RAG with autonomous agents that can reason about when and how to retrieve information, potentially querying multiple knowledge bases.
Fine-Tuned Retrieval Models
Moving beyond general-purpose embedding models to domain-specific, fine-tuned retrievers that better understand specialized terminology and concepts.
Conclusion
Building production-ready RAG applications requires careful attention to architecture, performance, and user experience. The combination of intelligent document processing, efficient vector search, and optimized generation creates powerful systems that can transform how users interact with information.
The key to successful RAG implementation lies in understanding the specific requirements of your use case, choosing appropriate technologies, and continuously optimizing based on user feedback and performance metrics. As the field continues advancing, RAG applications will become increasingly sophisticated, enabling even more natural and effective human-document interactions.
Whether you're building a PDF insight tool, a customer support system, or a research assistant, the principles and techniques outlined in this guide provide a solid foundation for creating RAG applications that deliver real value to users while maintaining the performance and reliability required for production environments.


